📍 간단 후기
🏷️ 수업
LLM을 배우기 위해서는 NLP, 즉 자연어 처리 방법에 대해서 배워야 한다. 이에 따라 8주 차에서는 NLP의 기본 개념부터 배웠다. NLP는 크게 다음과 같은 과정을 따른다.
자연어(처리 대상) 입력 -> [feature extraction -> 목적에 맞게 처리] -> 결과값 추출
여기서 앞에서 배운 머신러닝과의 차이점이 나온다. 머신러닝에서는 feature extraction과 같이 추출하는 기능은 없다. 하지만 딥러닝에서는 이 기능을 처리해 줌으로써 추출 및 처리를 한 번에 실행할 수 있다.
NLP를 배우는 과정은 다음과 같다.
(전처리 ->)토큰화 -> embedding -> 처리(Hugging Face) -> LLM 이용한 App(OpenAPI)
🏷️ 공모전
공모전은 바로 오늘(23일)이 마감일이었다. 어제 밤 10시까지 남아서 팀원분들과 기획서 작성에 집중했다. 전주에 프로젝트의 영향을 받아, 이번 주에 작성을 끝마치려 하니 좀 더 열심히 할 수밖에 없었던 주였다. 우리 조는 앱 개발에 힘써볼 예정이다. 이에 따라 어떤 기능을 추가할지, 어떤 차별점이 있는지, 또 우리 기술만의 장점을 하나하나 생각해보려 하니 생각보다 시간 소요가 더 많이 됐었다.
📍 좋았던 점
- 정규표현식

정규표현식은 표준 모듈인 re를 import해서 사용한다. 위 예시 이미지를 보면 알 수 있듯이, 실용적으로 쓰일 수 있을 것 같다. 문자열과 관련된 문제에 있어 하나의 방법으로 활용하기 좋은 형식이라고 생각이 들어 좋았다. 또 findall과 finditer를 통해 한 개의 단어가 아닌 원하는 만큼 단어 추출에도 사용할 수 있어 좋은 방법이 될 것이다.
- Tokenize

토큰화 과정을 하는 이유는 텍스트 데이터 전체를 구분하기 위함이다. 위 이미지의 주석을 보면 알 수 있듯이, 텍스트 데이터를 토큰화하기 쉽게 전처리 작업부터 진행한다. 여기서는 전체 단어를 소문자로 변환했다. 이후 문장 단위로 쪼개어 토큰화를 진행한다. 사용 Library는 NLTK이다. 자연어 처리를 위해 사용하는 대표적 파이썬 패키지이다. 이는 텍스트 토큰화/정규화/전처리 등을 처리하기 위한 기능을 제공해 주어 중요한 패키지라고 생각된다.
주요 Tokenizer 함수의 종류는 다음과 같다.
- sent_tokenize() : 문장 단위
- word_tokenize() : 단어 단위
- regexp_tokenize() : 토큰의 단위를 정규표현식으로 지정
위 예시 이미지는 문장을 단어 단위로 토큰화 하기 위해 word_tokenize() 함수를 사용한 것을 볼 수 있다.
NLTK의 단점은 영어 한정 토큰화가 가능하다는 점이다. 이를 보완하기 위해 나온 것이 KoNLPy이다. 여기서 사용하는 형태소 분석기 공통 메소드는 다음과 같다.
- morphs(string) : 형태소 단위
- nouns(string) : 명사만 추출하여 토큰화
- pos(string) : 품사를 부착 -> 형태소 마다 사용하는 품사 태그가 다르기 때문
확실히 한국어를 대상으로 하다보니, 명사와 어간, 품사 등을 추출하는 데 있어 더 세밀한 것을 볼 수 있다.
📍 부족한 점
- NLP_Embedding

NLP_Embedding은 크게 3가지로 나뉜다.
- Count-Based Word Representation : 단어 빈도수 기반 표현 ex) Bag of Word, TF-IDF
- Word Embedding : 고정된 vector로 표현. 같은 단어는 같은 값 ex) Word2Vec, Glove
- Contextual Word Embedding : 문맥을 고려해 vector로 표현 ex) ELMo, BERT, GPT2
NLP_Embedding을 해주는 이유는 Feature Extraction을 하기 위함이다. 여기선 Text를 Vector로 변환해 구분을 한다. 여기서 vector의 정확한 명칭은 Embedding vector가 된다. 위 이미지에서 보라색이 이에 해당한다.
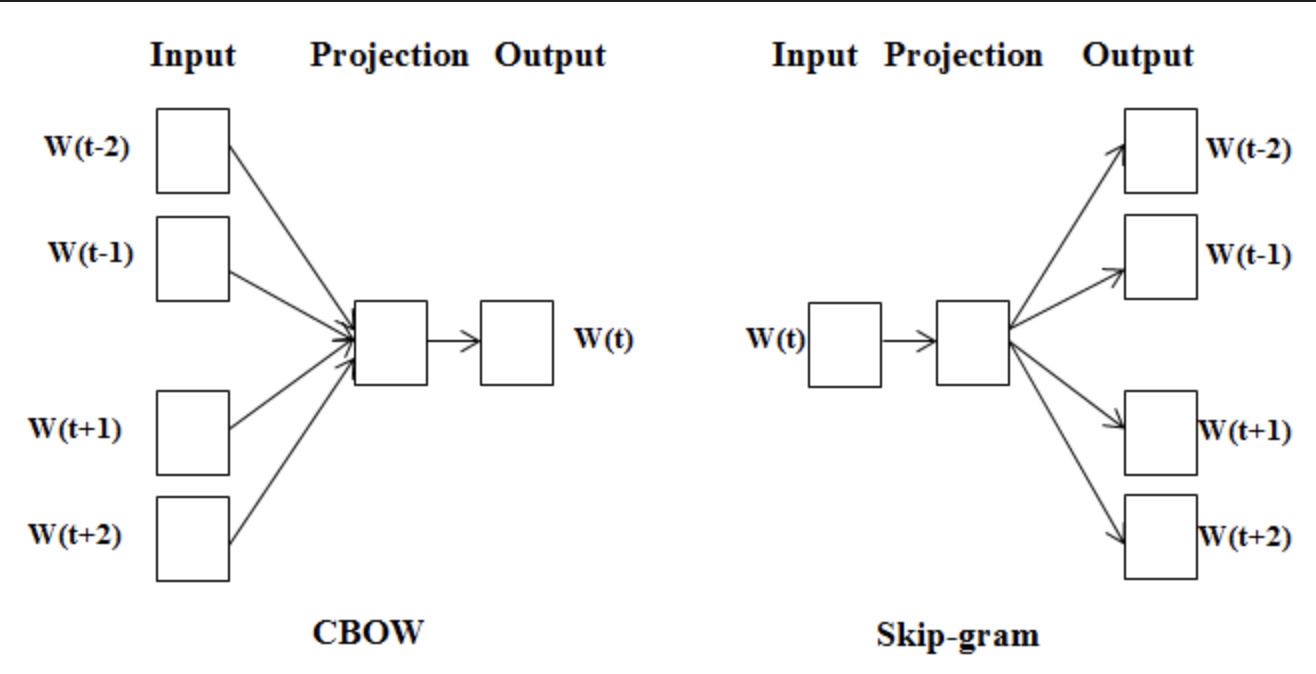
Word Embedding의 예시 중 하나인 Word2Vec은 크게 CBOW와 Skip-gram으로 나뉜다.
- CBOW : 주변 단어들을 통해 중심 단어가 뭔지 파악
- Skip-gram : 중심 단어를 통해 주변단어 파악
더 쉽게 얘기할 수 있는 예시는 다음과 같다.
CBOW는 one hot vector를 입력값으로 받고 중심 단어의 one hot vector를 출력값으로 받아 학습을 진행한다. 그래서 단어 index만 1, 나머지는 0으로 구성된다.
Skip-gram도 마찬가지로 one hot vector들로 모든 token들이 구성된다. 그리고 sliding window 방식으로 이동해 중심단어와 그 주변단어 쌍으로 Dataset을 구성한다.
(주변의 단어를 window라고 생각하여, 단어들을 쓸면서 탐색한다고 하여 sliding window라고 생각하면 이해하기 쉬울 것이다.)
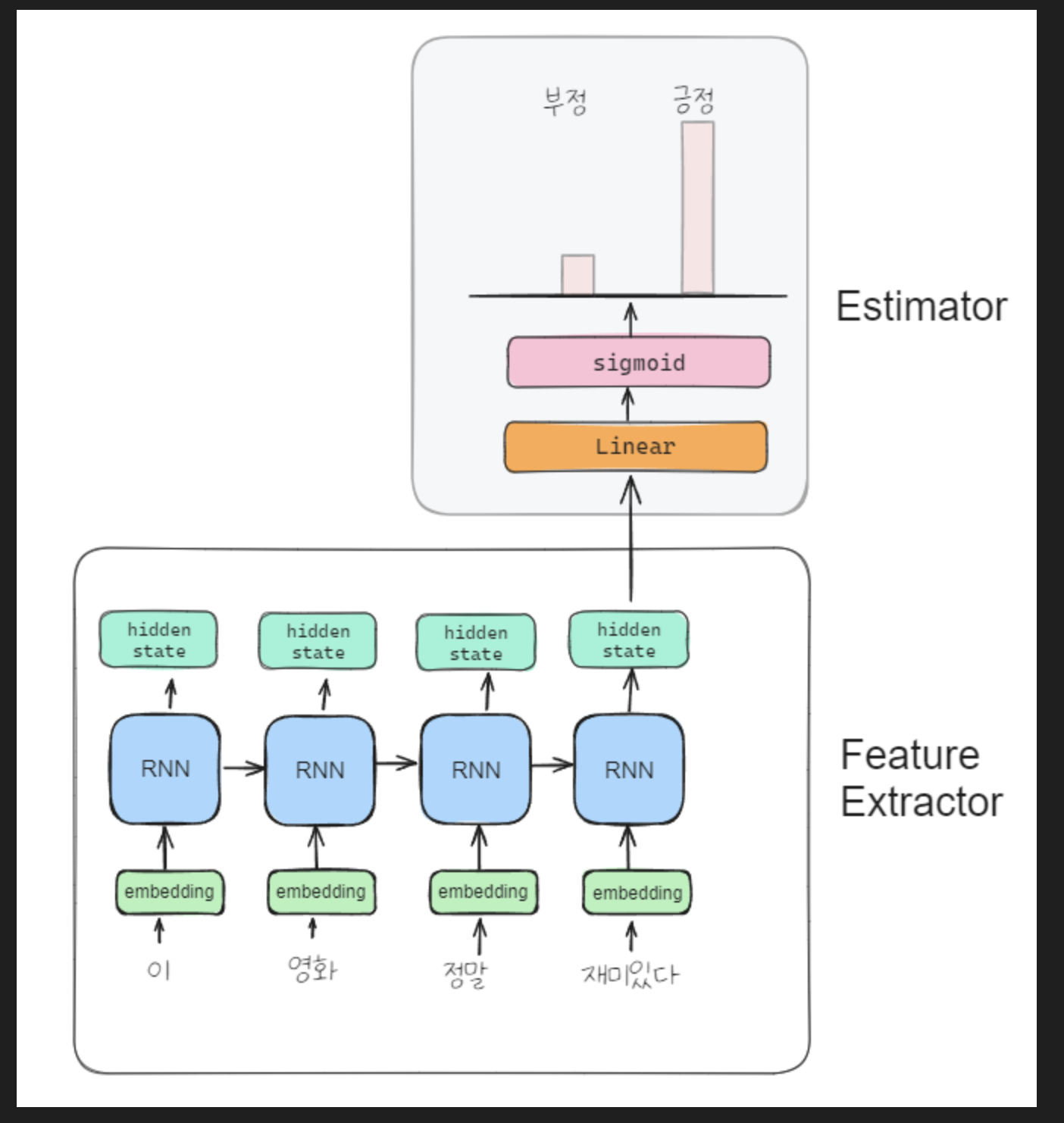
Contextual_word_embedding을 한 단어로 정리하자면 RNN이다. 이를 위해 RNN의 구조를 예시 이미지로 들었다. RNN은 sequential data를 통해 다음 단어를 추측한다. 위 이미지에서 보면, '이', '영화', '정말', '재미있다'와 같이 한 문장을 4개로 토큰화를 진행한 후 RNN을 통해 처리해 결괏값을 추출해 낸다. 따라서 '이'라는 단어가 나와서 가중합을 구해야 다음의 '영화'라는 단어를 추출(계산)할 수 있는 것이다.

RNN을 이해하기 위해 필기를 진행했다. sequential 이다 보니, 이전 값에 따라 값이 바뀐다. 이때 사용하는 activation 함수가 tanh(hyperbolic tangent)이다. (여담으로 ReLU 함수를 쓰지 않은 이유는, RNN이 더 이전에 나왔기 때문에 sigmoid 함수로 기울기 소실 문제를 해결하기 위해 tanh 함수를 사용했다고 한다.) 여기서 h가 hidden state이다. 이전에 배운 hidden layer라고 생각하면 이해하기 쉽다.
## Layer(계산 함수)를 어떤 걸 쓰냐에 따라 구분 가능
-> RNN : Recurrent Layer
-> CNN : Convolution Layer
-> DNN : Fully Connected Layer
-> Transformer : Tranformer Layer
📍 성찰 및 마무리
공모전 준비가 가장 큰 이슈였던 한주였다. 다음 주 월요일에 있을 코딩 테스트 스터디에 맞춰 코딩 테스트 문제도 주말에 풀어야 될 것 같다. 수요일에 있을 코딩 테스트 시험도 준비할 겸 열심히 준비해야겠다. 열심히 준비한 만큼, 좋은 결과가 따랐으면 좋겠다.
왠지 모르겠지만 시간이 딱딱 맞아지는 걸 보니, 시간을 잘 활용하고 있는 것 같다는 생각이 든다. (물론 운동 횟수가 줄어드는 건 참혹한 결과다....)
수업 내용이 최근 들어 또 이해하기 힘들어지는 것 같다. 필기를 더 많이 해보면서 이해해야 될 것 같다는 생각이 든다.
한주를 마무리하며 그 한주를 뒤돌아봤을때 후회되지 않는다면 그건 괜찮은 한 주를 보낸 거라고 생각한다. 결과물을 내며 시간을 보내고 있는 주가 많아짐에 따라 뿌듯함과 자신감이 늘어나는 시간을 보내고 있어 기분이 좋다. 다음 주도 이번 주처럼 열심히 살아봐야겠다.(운동은 더 많이..!)
'[SKN FAMILY AI CAMP] > 주간' 카테고리의 다른 글
| 🐉 SKN FAMILY AI CAMP 13기 12주차 후기 (2025.06.09 ~ 2025.06.13) (2) | 2025.06.13 |
|---|---|
| 🐉 SKN FAMILY AI CAMP 13기 11주차 후기 (2025.06.02 ~ 2025.06.05) (2) | 2025.06.05 |
| 🐉 SKN FAMILY AI CAMP 13기 8주차 후기 (2025.05.12 ~ 2025.05.16) (4) | 2025.05.16 |
| 🐉 SKN FAMILY AI CAMP 13기 7주차 후기 (2025.05.07 ~ 2025.05.09) (2) | 2025.05.09 |
| 🐉 SKN FAMILY AI CAMP 13기 6주차 후기 (2025.04.28 ~ 2025.05.02) (1) | 2025.05.02 |