📍 간단 후기
🏷️ 수업
Pytorch를 이용한 딥러닝 실습을 주로 다뤘다. 실질적 데이터를 이용해 시각화도 진행했다. 그 첫번째로는 MNIST Dataset을 활용한 Dataset 분석이다. 딥러닝 입문의 정석이라고 생각한다. 프로그래밍의 print("Hello World")와 같다고 생각한다. 그래도 딥러닝의 기본인 만큼 작동 원리를 빼먹지 않고 기억할 필요가 있다. pytorch에서 제공해주는 DatatLoader 함수라던가, torchvision 라이브러리를 활용해 transform을 하는 등의 원리 등도 파악해 둘 필요성이 있다고 느꼈다.
🏷️ 공모전
주제를 구체화 하였다. 그에 따른 데이터도 각자 역할을 정해 구해왔다. 공모전은 처음이긴 하지만, 아이디어 구상이 입상 결과에 있어 어느 프로젝트이든 거의 90프로 이상 차지한다고 생각한다. 물론 완주가 목표이고, 부족한 실력을 가지고 있지만 공모전을 진행하면서 괜히 희망이 생기는 주가 아닌가 싶다. Github Organization도 생성해 형상 관리도 진행할 예정이다.
📍 좋았던 점
- Train

전체적으로 보면
추론-> loss 계산 -> gradient 계산 -> parameter update -> gradient 초기화
과정으로 진행된다. 모델 호출을 통해 추론을 진행하는데, 이때 forward 함수를 불러와 모델을 재정의하는 방식이 인상깊은 점이었다.
- 모델 정의
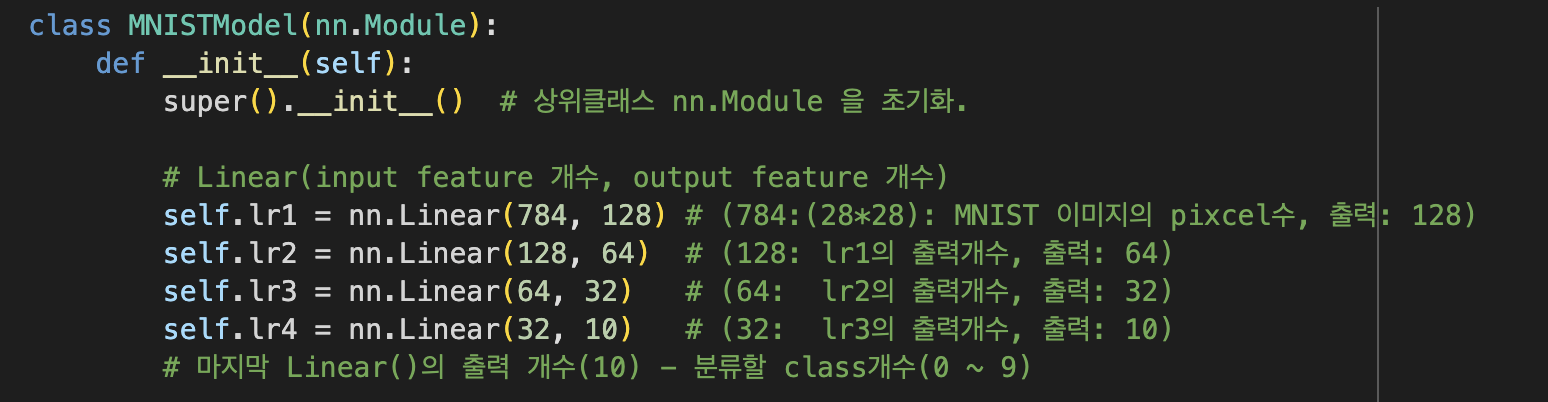
모델 정의하는 부분이 가장 key point라고 생각한다. 그만큼 이해하기도 쉽지 않았다.
먼저 init을 통해 nn.model을 초기화 한다. 이때 nn.Linear를 통해 feature의 개수를 줄여나가면서 출력 및 초기화를 진행한다. 줄이는 과정에서는 ReLU 함수를 사용한다. ReLU 함수를 사용하는 이유는 선형함수를 줄여 다시 선형함수에 집어 넣으면 결국 직선함수로 직결될 것이다. 이에 따라 비선형 함수인 ReLU 함수를 통해 방지해주는 역할을 진행한다.
- Data Loader

Data Loader 함수를 이해하기 위해 필기한 흔적을 캡쳐해 보았다. 딥러닝 과정은 대체적으로 Pipeline을 사용한다. 그 이유는 역시 속도 문제이다. 빠른 속도로 학습하기 위해서는 Pipeline이 필수 요건이다. DataLoader에서는 trainset, batch_size가 필수로 들어가야 한다. 여기서 train_loader 수는 epoch 수, test_loader 수는 step 수라고 정의하였다.
- 1 epoch : 한번 학습한 단위(한바퀴)
- 1 step : 1 batch_size 동안 학습한 단위 -> 실제 학습량으로 많이 쓰임
epoch과 step이 나중에 헷갈릴 수도 있기에 미리 정리해 두었다.
📍 부족한 점
- Train : Feature 수
설명을 쉽게 하기 위해 모델 정의 과정에서의 이미지를 다시 한번 빌린다. 처음에는 feature 수가 줄어들면 특징이 구체화되는 방향으로 진행된다고 이해했다. 하지만 너무 애매한 이해라고 생각해서 강사님께 질문했다.
- 내 이해 방식 : 고양이 몸처럼 보인다 -> 고양이 털처럼 보인다 -> 고양이 눈처럼 보인다 -> ..... -> 고양이다!
- 강사님 설명 : 고양이 이미지 -> 배경 및 주변환경 삭제 -> ...... -> 고양이다!
어떻게 보면 구체화라고 볼 수 있는데, 컴퓨터가 학습을 진행하는 과정을 알수는 없다는 것이 결론이다. 결국 output Layer를 추출해 내어 결론만 도출하는 것이 딥러닝의 역할이므로 이러한 과정을 받아들여야 하는 것 같다.
- Layer

Layer는 크게 다음과 같이 나뉘어져 있다.
- Input Layer
- Output Layer
- Hidden Layer
여기서 Input Layer는 바로 위 모델 정의 과정 이미지를 빌리자면 784가 된다. 그리고 Output Layer는 마지막 feature 수인 10이 되는 것이다. 이때 중간에 들어있는 feature 수들이 Hidden Layer이다. 이처럼 가장 많은 수를 차지하는 Hidden Layer인 만큼, 정답 추론을 위해서는 가장 중요한 요소임을 명심할 필요가 있다.
또한 Layer의 목적이나 구현 방식에 따라서도 구분이 된다.
- Fully Connected Layer : 위에서 봤던 Layer 처리. 입력 feature 수 지정 필요
- Convolution Layer : 이미지 feature extraction 시 사용
- Recurrent Layer : sequetial 에서의 feature extraction 시 사용
- Embeding Layer : Text(LLM 등) 에서의 feature extraction 시 사용
각 데이터에 맞게 최적의 Layer를 사용하지만, 작동 원리는 비슷하다는 점을 알아두자.
📍 성찰 및 마무리
저번주부터 수업 내용을 열심히 들어야겠다고 생각하다보니, 막상 어렵다고 생각되는 부분은 크게 없었다. 물론 실습 위주이거나, 개념 위주가 아닌 수업이 아니지만, 그래도 쉽게 이해하기는 쉽지 않았다. 전체적으로 개념 위주였던 한주였다.
다음주부터는 프로젝트가 진행된다. 이에 따라 수업도 수업이지만, 공모전 및 개인 공부 시간을 알뜰히 조정하면서 살아야겠다고 생각한다. 매주 말하지만, 시간 싸움인 것 같다. 시간을 어떻게 활용하느냐가 부트캠프 과정에서 살아남는 주요 포인트가 아닌가 싶다.
'[SKN FAMILY AI CAMP] > 주간' 카테고리의 다른 글
| 🐉 SKN FAMILY AI CAMP 13기 9주차 후기 (2025.05.19 ~ 2025.05.23) (2) | 2025.05.23 |
|---|---|
| 🐉 SKN FAMILY AI CAMP 13기 8주차 후기 (2025.05.12 ~ 2025.05.16) (4) | 2025.05.16 |
| 🐉 SKN FAMILY AI CAMP 13기 6주차 후기 (2025.04.28 ~ 2025.05.02) (1) | 2025.05.02 |
| 🐉 SKN FAMILY AI CAMP 13기 4주차 후기 (2025.04.14 ~ 2025.04.18) (0) | 2025.04.18 |
| 🐉 SKN FAMILY AI CAMP 13기 3주차 후기 (2025.04.07 ~ 2025.04.11) (0) | 2025.04.14 |