📍 간단 후기
🏷️ 수업
저번주 금요일부터 월요일 까지 3차 프로젝트를 진행했다. 우리팀 주제는 각종 플랫폼 사용 시 국내/외 저작권 관련 Q&A 챗봇을 만드는 것이었다. LangGraph를 사용해서 프로젝트를 진행했는데, 생각보다 그래프 구조 짜는 것이 수월하지 못해 애를 먹었다. '어떤 구조가 가장 효율성있는가?' 가 중요 포인트이다.
프로젝트가 끝난 이후에는 웹 프로그래밍에 대해 배웠다. 이번주는 Front-end에 대해 배웠는데, 기본적인 CSS, JavaScript 등 HTML의 구조 및 간단 실습을 진행했다. CSS는 bootstrap을 이용하여 수업을 진행했다. 금요일에는 Django Framework에 대한 수업을 시작했다. 서버 구조 및 역할에 대해서 수업을 진행해서 그런지 서버에 대한 이해를 통해 프레임워크를 배울 수 있겠다는 생각이 든다.
📍 좋았던 점
- CSS
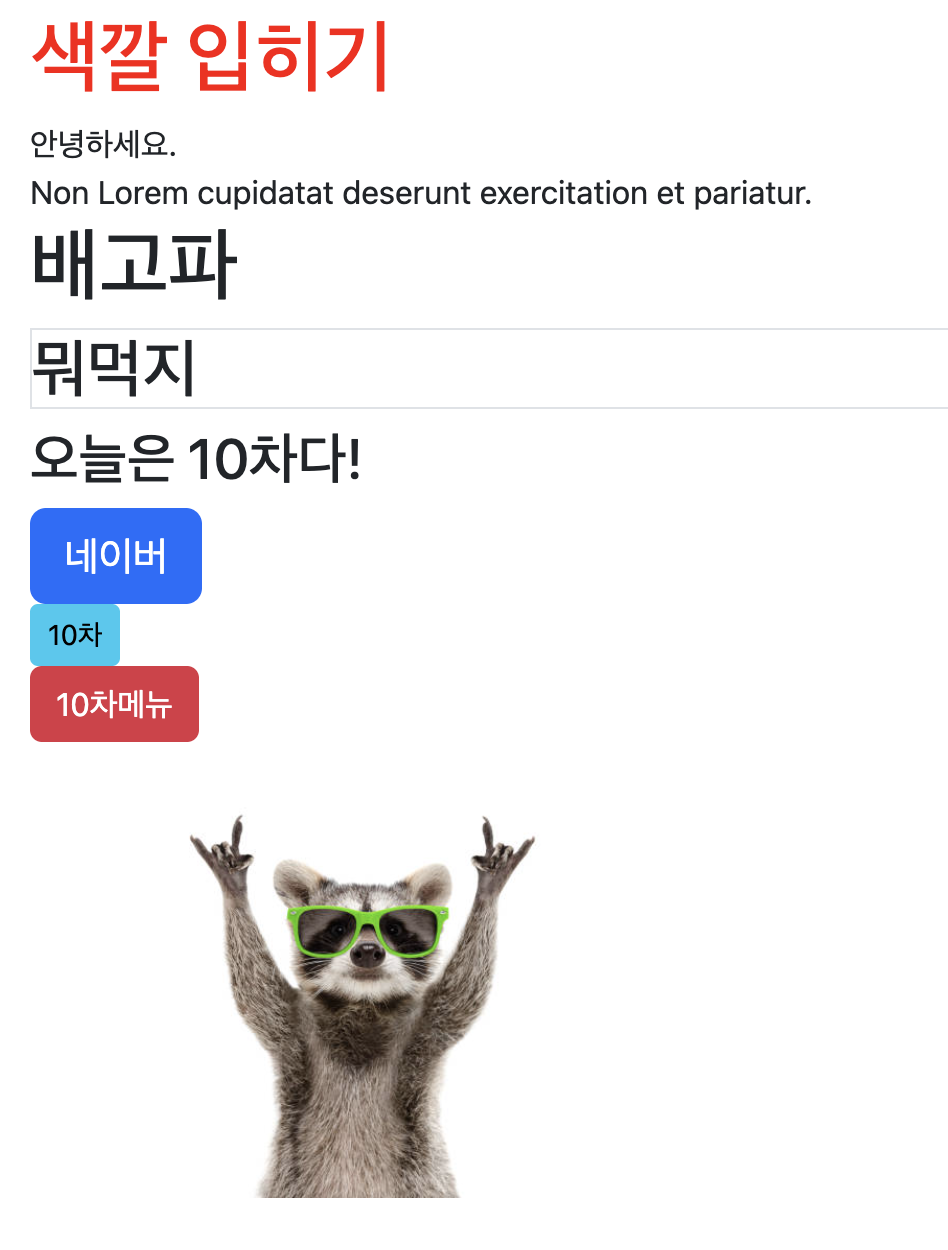
- Javascript

- Django
**
pip install django
pip install pillow
pip install django-bootstrap5
**
- HTTP요청 방식
- GET : HTTP의 기본 요청 방식 / 요청 파라미터를 주소 뒤에 배치 / 목적 : 서버가 가진 데이터 요청
- POST : 문자열 뿐 아니라 파일도 전송 가능 / 바디 부분에 요청 파라미터를 배치 / 목적 : 서버에 데이터 전송
- *** PUT은 전체적으로 바꿈 / Patch는 부분적으로 바꿈
HTTP 응답 정보 : HTTP가 원하는 응답 형식 -> 응답라인 / 헤더 / 응답 BODY
HTTP 상태 정보는 아래와 같다.
- 1xx (정보): 요청을 받았으며 프로세스를 계속한다
- 2xx (성공): 요청을 성공적으로 받았으며 인식했고 수용하였다
- 3xx (리다이렉션): 요청 완료를 위해 추가 작업 조치가 필요하다
- 4xx (클라이언트 오류): 요청의 문법이 잘못되었거나 요청을 처리할 수 없다
- 5xx (서버 오류): 서버가 명백히 유효한 요청에 대해 충족을 실패했다

웹 어플리케이션 서버에는 실행환경이 구축되어있어야 한다. 어떤 환경에서 실행했는지에 따라 달라지기 때문이다. 이를 위해 통합 기능을 제공해주는 실행환경 프로그램이 존재한다. (ex) 파이썬 - uWSGI)
Web 기반에서 실행되는 Application은 Web Site(정적 서비스) + CGI(동적 서비스)를 통해 이루어져 있다.
장고의 특징 중 가장 중요한 특징이 MVT 패턴 구조로 개발을 한다는 점과 ORM을 이용한 DB 연동을 지원한다는 점이다.
- MVT 패턴 : Model / View / Template -> 전체 프로젝트의 구조를 역할에 따라 분리해서 개발할 수 있다.
- ORM(Object Relational Mapping) : 객체와 관계형 데이터베이스의 데이터를 자동으로 연결해서 SQL문 없이 CRUD를 작성할 수 있다.

위 이미지를 보면 알 수 있듯이, 역할을 분리해서 기존 workflow에서 처리되던 작업들의 과정을 축약시킬 수 있다. Django는 이 구조를 기반으로 작업하기 때문에 장점이라고 볼 수 있다. 기능을 나눠서 구현하다 보니 역할이 나뉘어져 있는 게 더 잘 보일 것이다.
위 구조에서 중요한 점은 웹 클라이언트이다. 웹 클라이언트에서 사용자가 요청하면, View에서 응답을 한다는 것이 핵심이다.
📍 부족한 점
- 3차 프로젝트

우리팀 System 구조는 위 이미지와 같다. 플랫폼은 보이는 바와 같은 종류들을 사용했고, PDF 파일 내에는 미국과 우리나라의 저작권 관련 내용이 있다. 사용자가 질문을 입력하면 HyDE방식을 통해 검색을 진행한다. 이후 LLM/Tools/Vectorstore 3가지 중 가장 적절한 과정에 맞춰 답변을 생성한다. Vectorstore에는 각종 플랫폼의 저작권 관련 사이트를 크롤링 데이터, PDF 데이터를 저장해놓는다. 이때 메타데이터를 기준으로 문장 분류를 진행한다.
*** HyDE 방식 : 사용자 질문 입력 시 LLM을 통해 가상의 문서를 생성하고, 이와 DB에 있는 답과 비교해 유사도가 더 높은 답변을 생성한다.

우리팀 LangGraph 구조는 위 이미지와 같다. extract_name 노드를 통해 질문에 이름이 있다면 이름을 추출해준다. 이후 HyDE 노드를 거쳐 어느 방식을 쓸지 check하는 노드를 지난다. 이후 tool을 쓴다고 판단이 된다면 거기서 다시한번 llm을 쓸지 tool을 쓸지 판단하고 이후 tool을 어떤 걸 쓸지 확인한다. 마지막으로 synthesize 노드를 통해 최종 답변을 모아 답변을 도출한다.
RAG 활용을 기다리고 기다렸던 만큼, 이번 프로젝트에서의 RAG 활용은 정말 뜻깊었다. 반면 성능 개선에 있어서는 아직 생각해봐야 할 문제이다. HyDE 방식이 정확성에 있어서는 좋을 수 있지만, 답변 속도나 계산 비용 측면에서는 좋지 못하다는 점이다. 이는 사용자나 회사의 입장에서 굉장히 좋지 않은 상황이다. 또 ChromaDB를 사용했으나, 데이터와 속도는 반비례한다는 점도 고려해봐야 될 상황이다. 또한 기능적으로는 강력하겠지만, 각 턴마다 여러 노드를 거치고, LLM API를 호출하므로 비용 측면에서는 매우 좋지 않은 모델이라는 점에 고민을 많이 해봐야겠다.
📍 성찰 및 마무리
다음 프로젝트때는 Django Framework를 사용해서 3차 프로젝트 고도화 예정이다. 이때 방식을 바꾸던, DB를 바꾸던 고심해서 프로젝트를 진행해야겠다.
또 RAG에 이어 Django Framework도 기대했었다. 이에 다음주 수업 내용도 더욱 집중하면서 수업에 임할 수 있을 것 같다.
이제 3개월차가 된다. 열심히 해보며 시간을 보냈다.(정신없이...가 맞는 말인가?) 그렇지만 자기소개서를 작성하다보니 여전히 자신감이 넘치지는 않다. 아직 배운 내용들이나 해온 프로젝트의 이해구조가 확립되지 않아서 드는 생각인 것 같다. 이제 슬슬 원서 넣고 취업 시즌이 다가오기 때문에 더욱 정신 차리고 머릿속을 정리해야겠다는 생각이 든다. 항상 자신감을 가지면서 살자는 마음을 다짐하며 마무리한다.
'[SKN FAMILY AI CAMP] > 월간' 카테고리의 다른 글
| 🐉 SKN FAMILY AI CAMP 13기 AI 부트캠프 수료 후기 (2) | 2025.09.18 |
|---|---|
| 🐉 SKN FAMILY AI CAMP 13기 24주차(5개월차) 후기 (2025.09.01 ~ 2025.09.05) (2) | 2025.09.07 |
| 🐉 SKN FAMILY AI CAMP 13기 19주차(4개월차) 후기 (2025.07.28 ~ 2025.08.01) (10) | 2025.08.01 |
| 🐉 SKN FAMILY AI CAMP 13기 10주차 (2개월차) 후기 (2025.05.26 ~ 2025.05.30) (2) | 2025.05.30 |
| 🐉 SKN FAMILY AI CAMP 13기 5주차 한달 후기 (2025.04.21 ~ 2025.04.25) (0) | 2025.04.25 |