📍 간단 후기
🏷️ 수업
저번주와 마찬가지로 NLP의 Embedding 관련한 수업을 진행했다. GRU 모델을 기반으로 한 간단히 챗봇을 만들어 보며 RNN 수업을 마무리한 한 주다. 전반적으로 수업 내용이 개념 설명 위주였다. 개념 자체가 신경망을 기반으로 하거나 Layer를 기반으로 하는 내용들이었기 때문에 대부분 이해하기 힘든 내용이었지 않았나 싶다.
🏷️ 코딩 테스트
월요일에 코딩 테스트 스터디를 진행했다. 일주일 반 정도의 시간이 있었기 때문에 15문제 정도를 배부했었다. 이번에는 같이 한번 봐야되는 문제부터 간단 코드 리뷰한 후 어려운 문제 하나를 시간을 가져 같이 푸는 방식으로 진행했다.
수요일에 처음으로 코딩 테스트라는 걸 봤다. 물론 PCCE라서 기초 기반 테스트였지만, 환경이나 진행 방식, 난이도 등이 궁금했어서 신청한 이유도 있었다. 다음달부터는 PCCP로 넘어가야겠다는 후기를 남긴다.
📍 좋았던 점
- seq2seq
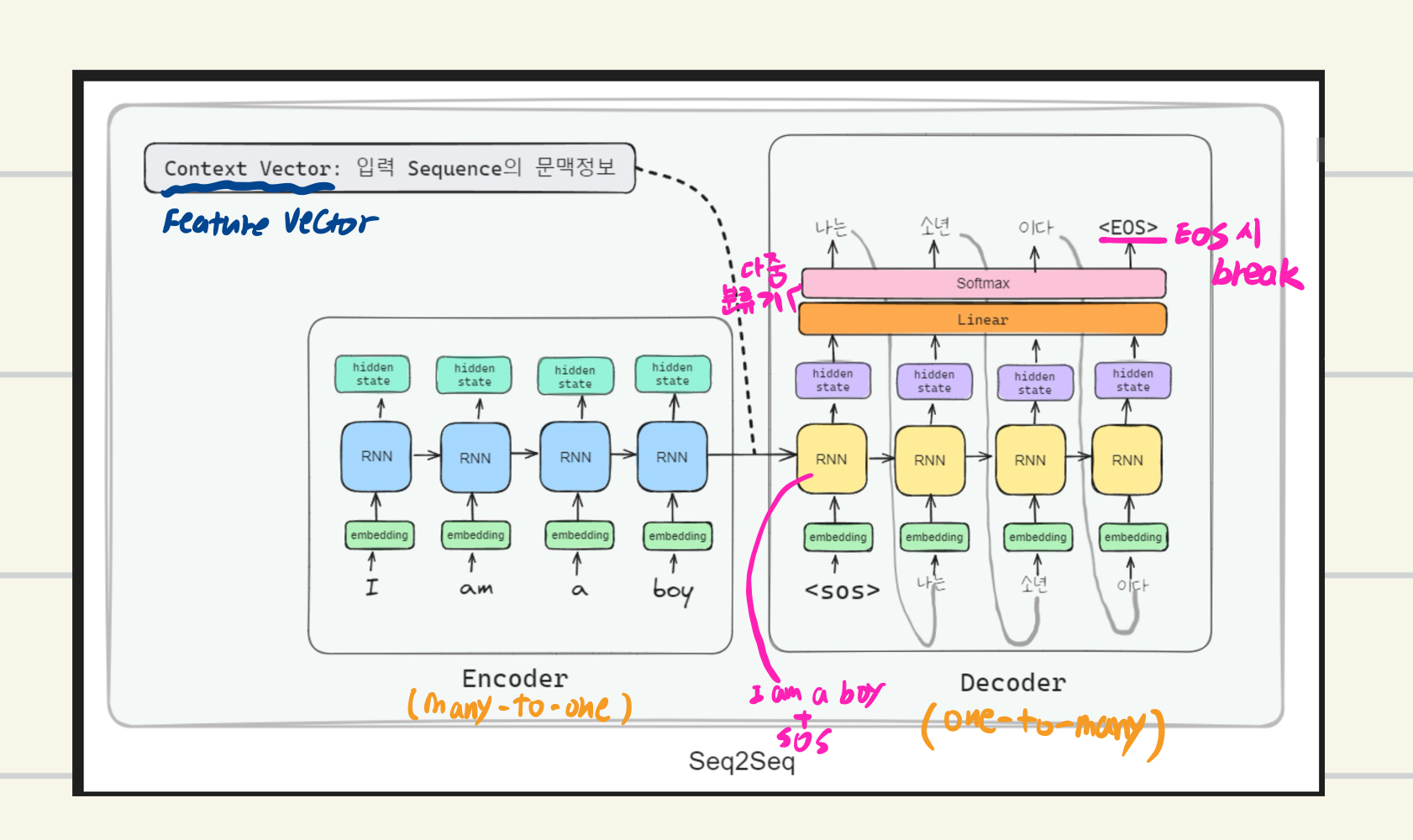
seq2seq를 이해하기 전에, GRU에 대한 개념이 필요하다 GRU란 LSTM과 RNN의 한계점인 기억력 소실문제를 개선하기 위해 나온 모델이다. 이에 따라 이전 시점을 기억하기 위해 나온 구조가 seq2seq라고 이해하면 되겠다. 위 이미지를 보면 알 수 있듯이 Encoder과 Decoder로 이루어져 있다. 따라서 seq2seq는 Encoder-Decoder 구조를 RNN 계열에 적용한 모델이다.
Encoder는 전체 Feature(특징)을 표현하는 context vector를 출력한다. 답변할 때 필요한 feature라고 생각하면 된다.
Decoder는 Encoder의 최종 feature vector 값을 받아 결과를 생성한다.
여기서 알 수 있듯이, Encoder는 질문 분석에 특화되었고, Decoder는 답변 생성에 특화됐다고 이해하는 것이 좋을 것이다.
📍 부족한 점
- Attention Mechanism
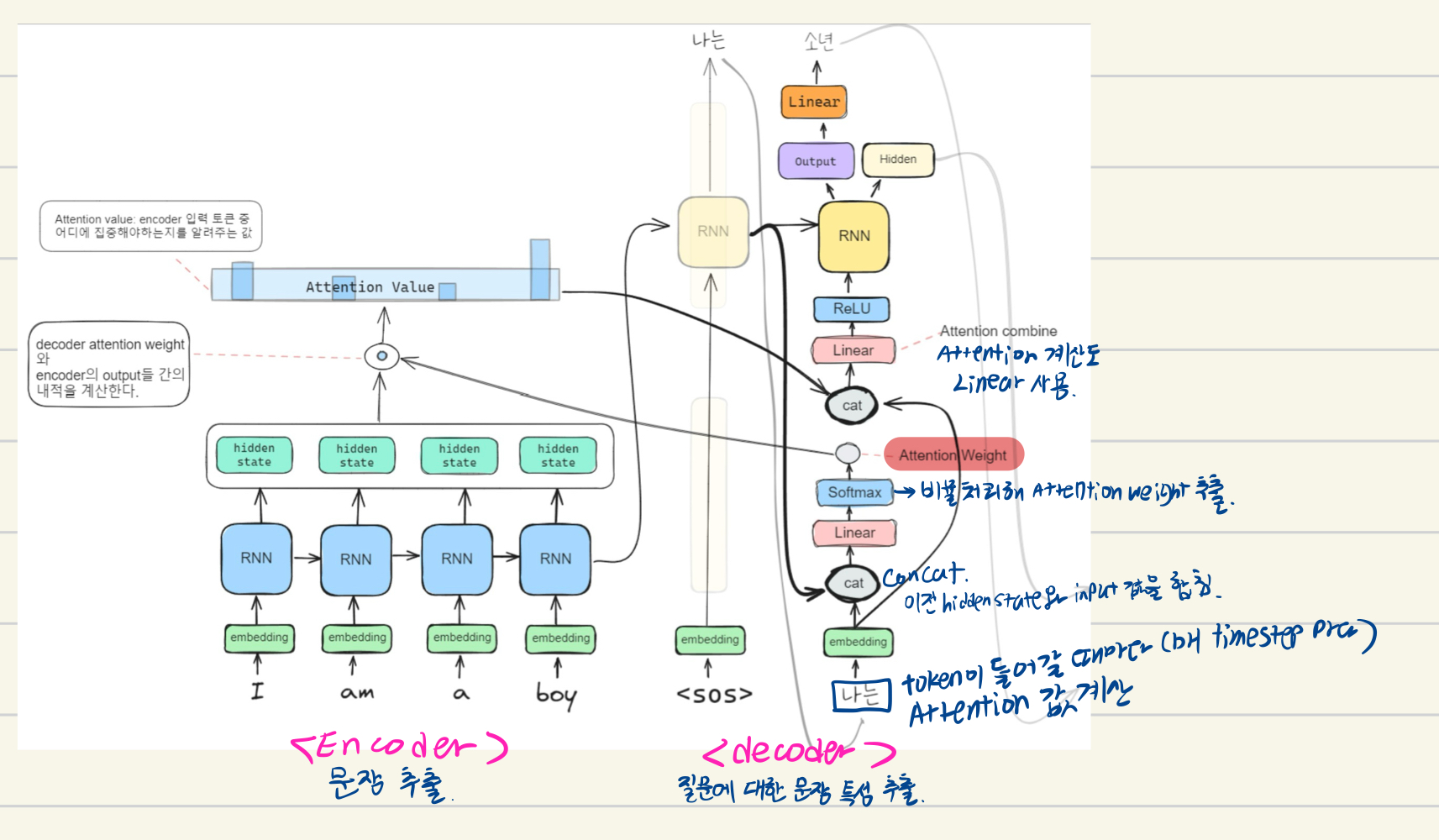
Attention Mechanism은 GRU의 문제점을 보완한 모델이다. 기존 모델은 모든 문장을 토큰화해서 적당한 비율을 주어 Feature를 추출했다. 그러나 단어마다 중요도가 다를 것이다. 이에 따라 나온 모델이 Attention Mechanism이다. 따라서 매 timestep마다 Encoder의 입력문장을 다시 참고한다. 이후 예측해야 할 단어와 연관있는 입력 부분에 더 집중하려고 하는 것이 Attention Mechanism이다.
위 이미지를 하나하나 분리해보겠다.
먼저 Encoder에서는 기존과 같이 RNN Layer(계산함수)를 통해 각 단어에 대한 feature vector를 추출한다. 이후 Decoder에서 한 단어(token)에 대한 값과 feature vector를 concat을 통해 합친다. 이후 Linear 함수를 통해 계산하고, softmax 함수를 통해 비율로 처리하여 Attention Weight를 추출하여 Decoder에서 다음 단어를 추출하기 전에 Attention value를 계산한다. 이렇게 Attention Weight를 token이 들어갈 때마다 구하여 다음 단어를 추출하는 방식이 Attention Mechanism이 되는 것이다.
- Transformer

seq2seq를 활용하는 Attention Mechanism에도 어김없이 찾아오는 문제점이 있다. 바로 병렬처리를 하지 못해 속도가 느리다는 점이다. (문제점은 왜 자꾸 끊임없이 발생하지...)
그래서 또 그 점을 보완해주는 개념이 Transformer이다. Transformer는 Encoder와 Decoder에서 RNN Layer를 제거하고 Attention으로 변경한다. 그러면 각 Encoder와 Decoder가 Layer로 쌓여 넘겨줄 때마다 feature 추출이 가능해져 속도가 빨라지는 것이다.
위 이미지를 보면 알 수 있듯이, 큰 네모가 각각 Encoder와 Decoder의 Transformer Layer이다.
Transformer는 Batch Normalization 개념을 착안한다. 이를 통해 각 Layer마다 스케일링을 진행한다. 이에 성능을 높이는 방식이다.
**Linear는 스케이링을 하면 할수록 성능이 좋아진다.

self attention은 자신의 문장을 통해 feature를 추출한다고 생각하면 된다. 그러면 각 단어의 연관성을 파악해 해당 단어의 attention weight를 파악할 뿐 아니라 더 다양한 feature를 얻을 수 있다.
위 이미지를 보면 알 수 있듯이, Input이 3개로 나뉜다. 과정은 다음과 같다.
Query와 Key 간의 내적을 통해 유사도를 구한다. -> Matmul이라는 행렬곱을 해준다. -> 스캐일링 -> softmax 함수 처리 -> 남은 입력값인 Value와 Matmul을 해주어 최종 feature를 추출한다.
📍 성찰 및 마무리
이렇게 2달이 흘렀다. 솔직히 다들 빨리 지나간다 뭐다 하지만, 왜 빠르지 않았던 것 같은지 모르겠다. 한 것들이 많아서 시간은 빨리 갔을지 몰라도 뒤돌아보면 전혀 빠르지 않았다. 이제 슬슬 코딩 테스트 실전에 준비해야할 필요성을 느꼈다. 앞으로는 카테고리별로 문제를 풀 예정이다. (DFS 문제, BFS 문제, .....) 또 취업을 목적으로 왔기 때문에 내가 했던, 앞으로 내가 할 프로젝트에 대한 개념 및 사용 라이브러리 등을 공부할 필요가 있겠다. 이제 3달 차로 진입함에 따라 선택과 집중을 잘 해야 될 필요성을 느끼며 다음주를 시작할 준비를 해야겠다.
'[SKN FAMILY AI CAMP] > 월간' 카테고리의 다른 글
| 🐉 SKN FAMILY AI CAMP 13기 AI 부트캠프 수료 후기 (2) | 2025.09.18 |
|---|---|
| 🐉 SKN FAMILY AI CAMP 13기 24주차(5개월차) 후기 (2025.09.01 ~ 2025.09.05) (2) | 2025.09.07 |
| 🐉 SKN FAMILY AI CAMP 13기 19주차(4개월차) 후기 (2025.07.28 ~ 2025.08.01) (10) | 2025.08.01 |
| 🐉 SKN FAMILY AI CAMP 13기 15주차 (3개월차) 후기 (2025.06.30 ~ 2025.07.04 (2) | 2025.07.04 |
| 🐉 SKN FAMILY AI CAMP 13기 5주차 한달 후기 (2025.04.21 ~ 2025.04.25) (0) | 2025.04.25 |