📍 간단 후기
🏷️ 최종 프로젝트
2주 좀 더 남았다. 이제 점점 마지막이 보이는 시기이다. 프로젝트의 뼈대도 어느정도 갖춰줘야 할 시기이다. 마지막이 다가오는 만큼, 머릿속이 복잡해지는 것은 사실이다. 되던 것이 안되고, 또 그 안에서 성공하면 기분 좋은 시기이다.
우리 팀은 서빙해야 될 모델들이 많아서 runpod에서 다 서빙을 진행해야 한다. 또 sLLM을 쓰고, on-premise 환경에서 작업을 진행하려 하다 보니, vectorDB에 값을 입력할 때 이용하는 임베딩 모델도 gpt가 아닌 허깅페이스 모델을 사용하려고 한다. 이렇게 사용해야 할 리소스 비용도 많이 필요하고, 배포할 때 필요한 비용도 있고, 여러가지로 머릿속이 복잡해진다. 모델들이 잘 연동되고 활용된다면 무척이나 기쁠 것 같다.
🏷️ 코딩 테스트 스터디
코테 스터디를 오랜만에 진행했다. 이번주는 해시 문제 3문제를 풀어왔다. 그리고 그 전 주에 하지 못한 스터디 내용도 문제 풀이를 진행했다. 전 주에는 Greedy algorithm과 정렬 문제 4문제였다.
그래도 코테 문제를 풀다 보니, 손에서 놓지 않고 있다는 점이 뿌듯했다. 다들 스터디를 마무리 지었지만, 우리는 미뤘던 주가 많아 다음주에 끝을 볼 예정이다. 최종 프로젝트 멘토링이 처음 진행될 때, 멘토님께서 하신 말씀이 있다. 매일 2문제 정도씩은 풀어서 손에서 놓지 말라고. 매일 2문제는 아니지만, 일주일에 몇문제씩 풀면서 손에서 놓지 않으려고 꾸준히 노력해야겠다.
📍 좋았던 점
- S3 연결
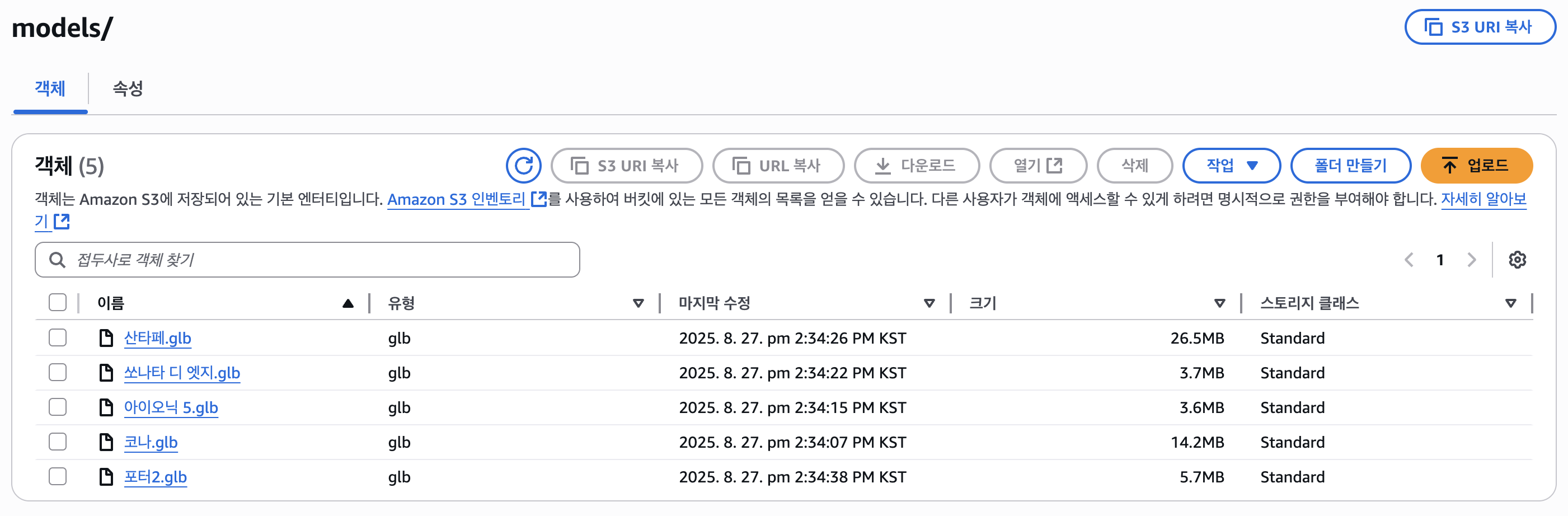
우리 프로젝트에서는 자동차들의 3D 이미지를 제공해준다. 이를 위해, 3D 이미지를 생성한 후 S3에 저장한다. 사용자가 자동차의 2D 이미지만 보는 것 보다는 3D이미지를 통해 다방면에서 확인할 수 있다는 측면에서 진행한 것이다.
S3자체를 처음 만져본다. 참고로, S3는 EC2와는 다르게 켜놓으면 돈이 나가는 시스템이 아니다. S3 자체가 대용량 저장 시스템이다 보니, 저장하는 만큼 돈이 청구된다. 다들 긴장하지 않아도 된다.
아직 5개밖에 생성을 못해서 저렇게 예시 이미지 5개만 두었다. 크기를 보면 알 수 있듯이, 컴퓨터에 이미지를 두고 사용하고, 팀원들과도 항상 git pull을 받아 사용하다 보면, 더이상 용량이 버티지 못할 것이다. 이를 위해 S3를 사용하는 것이다.

또 S3에 올린 데이터를 사용하기 위해서는 이렇게 .jsx 파일을 새롭게 만들고, .js파일을 수정해야 한다(react를 사용한다면). 아무래도 S3를 처음 이용해보는 입장에서는 이렇게 로딩되는 과정이 너무 재밌고 뜻깊었다.
- OAuth 활용 - Google

위 이미지는 구글 로그인을 처음 성공시킨 결과이다. 너어어어무 뿌듯했다. OAuth가 생소한 분들을 위해 설명 드리자면, 해당 서비스 내부에서 회원가입을 해도 되지만, 구글이나 카카오톡 처럼 다른 웹 사이트에서 로그인을 진행하는 과정이라고 보면 된다.
구글 로그인을 하기 위한 과정은 다음과 같다.
- 구글 API 키 발급
- https://console.cloud.google.com/auth 접속
- 프로젝트 생성 및 OAuth 2.0 클라이언트 ID 생성
- 이름 / 승인된 JavaScript 원본 링크 등록 / 승인된 리디렉션 URI 등록 및 저장
- admin 페이지에 클라이언트 ID 및 시크릿 키 저장
구글 로그인이 소셜 계정을 이용하면 되는거고, api 키만 이용하면 되는 거다 보니, 되게 쉽고 간단할 거라 생각했다. 반면 그렇지 않았다. 특히 redirection할 페이지 설정이 굉장히 중요하다. 이렇게만 말하는 걸 보면 상당히 쉬워 보이지만, 머릿속이 복잡해진다...

이유는 위 이미지를 통해 확인 가능하다. 회원을 장고 서비스가 본인의 회원이라고 인식해야 하기 때문이다. 이를 위해 테이블 연결도 진행해야 한다. 또 postgres에 잘 들어가는 지 확인하기 위해 이렇게 SQL문도 실행해서 확인을 진행했다.
- sLLM 파인튜닝

저번주와 같이 이번주도 sLLM 파인튜닝을 어김없이 진행했다. 위는 기존 데이터셋에 맞춰 파인튜닝을 진행한 결과이다. 상당히 미미한 발전을 한 것으로 보인다. 그래서 우리는 고민했다. 데이터를 더 수집해야 되나? 방법이 잘못됐나?
결론은 아래 이미지를 통해 보여드리겠다.

정답은 데이터셋 전처리이다.
확연하게 좋은 결과나 나오는 것을 확인할 수 있다. 위 이미지에서 CtxAcc는 문맥 참고 적중률이다. 이게 뭔지는 이제부터 설명 하겠다.
원래의 데이터셋의 구조는 다음과 같다.

역할이 user인지, 모델인지 알려주고, 그에 따른 QA를 주었다. 이후 context 필드에 해당 데이터 내용 전체를 모델에게 학습시켰다.

위 이미지는 개선된 데이터셋이다. 데이터 전처리 방식을 확 바꿨다.
(보기 쉽게 train데이터 셋 필드를 보여주었다.)
중점은 contexts에 있는 내용을 chunking했다는 점이다. chunking을 통해 500여개였던 데이터 qa쌍을 총 2900여개까지 늘렸다. 또 chunking한 문장 하나당 총 3개의 qa쌍을 만들었다. 이후 chunking한 내용을 바탕으로 contexts 필드를 구성했다. contexts 필드는 크게 3가지의 내용이 담겨있다. positive 1개, negative 2개로 이루어져 있다. positive는 해당 질문에 대한 chunking 문장이다. negative는 해당 질문을 제외한 chunking 문장을 임의로 선정한다. 다음으로 positive_index를 주어 어느 context 가 postive인지 표시한 다음, 파인튜닝을 진행할 때는 정답률이 얼마나 되는지 판단을 하는 것이다.
이것이 바로 CtxAcc이다.
이렇게 sLLM 결과가 좋게 나온 것을 끝으로 평가를 진행했다.
BertScore 결과는 아래 링크를 통해 확인할 수 있다.
SKN13-FINAL-3TEAM/evaluation/sLLM_quantitative.md at main · SKNETWORKS-FAMILY-AICAMP/SKN13-FINAL-3TEAM
Contribute to SKNETWORKS-FAMILY-AICAMP/SKN13-FINAL-3TEAM development by creating an account on GitHub.
github.com
다음으로 BertScore뿐만 아니라 CosineSimilarity를 평가했다.
SKN13-FINAL-3TEAM/evaluation/sLLM_quantitative_CosineSim.md at main · SKNETWORKS-FAMILY-AICAMP/SKN13-FINAL-3TEAM
Contribute to SKNETWORKS-FAMILY-AICAMP/SKN13-FINAL-3TEAM development by creating an account on GitHub.
github.com
이제 다음단계로는 정성평가를 진행해 볼 차례이다. sLLM 결과가 계속 좋게 나온 만큼, 성능 또한 좋아졌으면 한다.
📍 부족한 점
이번 주의 부족한 점은 최종 프로젝트 진행 과정에서 앞으로 남은 일에 대해 열거해 보려고 한다.
- vLLM
우리는 총 4개의 모델을 쓴다. 텍스트 생성 모델, 이미지 생성 모델(멀티모달), 3D 생성 모델, 영상 생성 모델이 포함된다.
runpod에 vLLM을 깔아서 model을 서빙해야 한다. 그렇지 않으면 생성 속도도 느릴 뿐더러 노트북 저장공간이 남아나질 않을 것이다.
python -m vllm.entrypoints.openai.api_server \
--model kakaocorp/kanana-1.5-8b-instruct-2505 \
--enable-lora \
--lora-modules kanana-finetuned=ki-student/kanana-finetuned-model-v1 \
--host 0.0.0.0
runpod에 LLM 모델을 서빙하는 명령어이다. 먼저 이를 위해 런팟 터미널에 pip install vllm을 해줘야 한다.
LoRA 방식으로 파인튜닝을 진행했으니 어뎁터도 같이 명령어에 입력해준다. 이렇게 하면 엔드포인트가 생성된다.
이때 주의해야 할 점이 있다. 바로 pods 생성 시 8000번 포트도 활성화해줘야 한다는 점이다. 나는 이 부분 때문에 모델 서빙이 30~40분 걸리는데 3번을 다시 했다...
이렇게 생성된 엔드포인트를 .env파일에 넣고 장고에 연결하는 방식으로 진행하면 된다고 한다. 아직 실행을 못시켜봐서 결과를 모르겠다..!
- Embedding 모델
간단 후기에도 말했듯이, 우리는 on-premise(힘드네..)를 고수하고 있다. 이에 따라 OpenAI에서 제공하는 gpt 모델을 사용해서 임베딩하지 못한다. 임베딩은 사용자의 요청을 처리하기 위해 사용되기도 하고, vectorDB에 데이터를 넣을 때도 사용되는 만큼, on-premise 영역에서는 철저하게 지켜져야 한다. 이에 따라 채택한 임베딩 모델은 다음과 같다.
BAAI/bge-m3 · Hugging Face
For more details please refer to our github repo: https://github.com/FlagOpen/FlagEmbedding In this project, we introduce BGE-M3, which is distinguished for its versatility in Multi-Functionality, Multi-Linguality, and Multi-Granularity. Multi-Functionalit
huggingface.co
해당 모델이 임베딩을 도와주어 우리가 그토록 고수하는 on-premise 환경을 유지할 수 있게 됐다. 이렇게 고도화하면서 text-pipeline을 해당 프로젝트에 적용하고, image-pipeline도 이와 같이 적용하다 보면 언젠가 우리 프로젝트가 완성될 것이다.
📍 성찰 및 마무리
생각보다 비용이 많이 소비된다. runpod 사용이 굉장히 큰 것 같다. 다음주 부터는 aws 서버에 배포 진행해야 하므로 해당 비용도 챙겨야 한다. 이제부터 큰 일만 남았다. 자신있게 프로젝트 성공할 것이라고 말하겠다.
시간을 더욱 더 촉박하게 써야될 것 같다는 느낌을 받았다. 이에 따라서 어떻게 하면 시간 효율이 잘 나올지 생각해 보는 것이 PM의 역할이라고 생각한다. 물론 내 개인적인 시간도 잘 계획해야 되겠다. 그래도 이번 달은 대체적으로 운동을 잘 갈 수 있어서 다행이다.
최근에 러닝을 시작했다고 말했는데, 요즘 뛰는 사람들이 부쩍 늘어나서(나도 그중 하나다.) 뛸 맛이 난다. 여러분들도 움직여라. 뛰어라. 운동해라. 라고 감히 말씀 드리겠다.!!
다음주에 해야 할 일은 다음과 같다.
- pipeline 연결
- vLLM 연동 확인
- EC2 서버 배포
- 문서 작업 마무리
우리에게 밤은 길다. 최종 프로젝트가 성공적으로 마무리 되길 빌며 글을 마치겠다.😪😪
'[SKN FAMILY AI CAMP] > 주간' 카테고리의 다른 글
| 🐉 SKN FAMILY AI CAMP 13기 25주차 후기 (2025.09.08 ~ 2025.09.15) (1) | 2025.09.17 |
|---|---|
| 🐉 SKN FAMILY AI CAMP 13기 22주차 후기 (2025.08.18 ~ 2025.08.22) (5) | 2025.08.22 |
| 🐉 SKN FAMILY AI CAMP 13기 21주차 후기 (2025.08.11 ~ 2025.08.14) (4) | 2025.08.18 |
| 🐉 SKN FAMILY AI CAMP 13기 20주차 후기 (2025.08.04 ~2025.08.08) (0) | 2025.08.10 |
| 🐉 SKN FAMILY AI CAMP 13기 18주차 후기 (2025.07.21 ~ 2025.07.25) (6) | 2025.07.25 |